

![]()
A SLAM filter reports a pose and a covariance. APE/RPE check the pose. smfeval checks whether the covariance is honest.
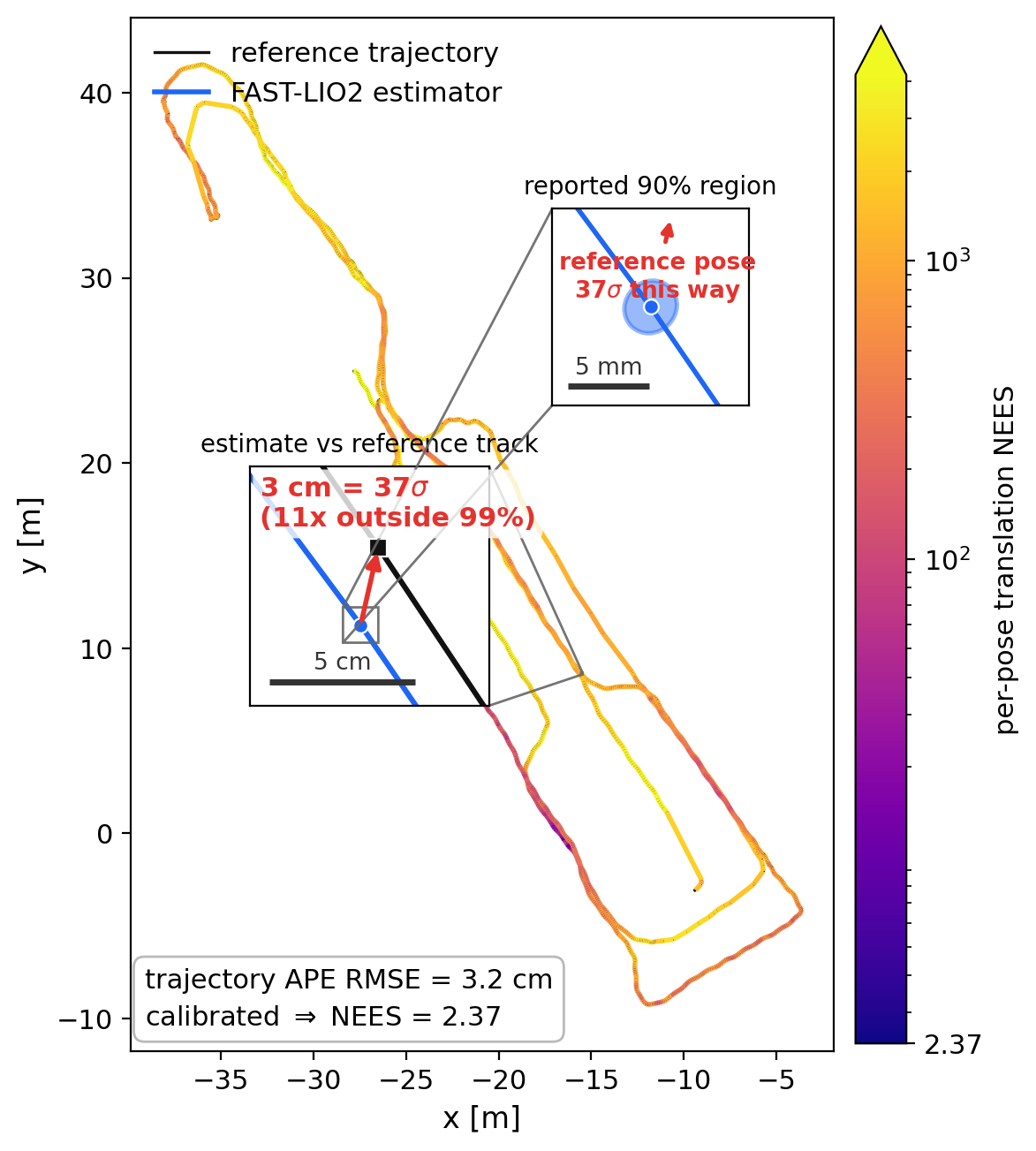
Illustration built in notebooks/figure_overconfidence.py, not smfeval
output. smfeval emits the text verdict below; the figure shows what that
verdict means geometrically. FAST-LIO2 on Oxford Spires christ-church-03. The estimate (blue) tracks the reference (black) to 3 cm APE, which is an excellent APE,
but the filter's reported 90% region is millimetres wide. The
reference lands about 11x outside even the filter's 90% region (the figure marks
this as 37 sigma). The belief is wrong where the mean is right, and that
per-pose gap is what smfeval scores. (Data: Oxford Spires, CC BY-NC-SA 4.0.)
The notebook reproduces the headline verdict on one Oxford Spires sequence end to end (install, fetch data, verdict, NEES-vs-reference plot).
pip install smfevalThe only dependencies are NumPy and SciPy (Python 3.10+).
$ smfeval nees estimate.SQUARE reference.tum --ref-body-frame lidar
median NEES 1.04e3 (calibrated: 2.37)
covariance scale gap k = 441, ~21x too tight per axis
90% coverage: 0.000 (calibrated: 0.900)
FAST-LIO2 on Oxford Spires christ-church-03. See
exporters/fast_lio2/VALIDATION.md for the full reproduction.
No
.SQUAREfile? smfeval needs a covariance for every pose, not just the poses, but it does not need the SQUARE format. If your filter outputs covariances, pass a plain TUM file plus a--covsidecar. If it does not, Your filter doesn't write SQUARE yet? shows how to get them.
Under a calibrated belief the per-pose translation NEES has a known reference
median of 2.37 (NEES is the error measured in standard deviations, squared).
The scale gap k = median NEES / 2.37 is the factor by which the published
covariance is too tight, so each axis is off by about a factor 21.
Here the filter's 90% credible ellipsoid never contains the reference. smfeval score goes further. It localizes the regime that is wrong (bulk vs tail) and
emits structured diagnoses with recommendations.
$ smfeval pair a.SQUARE b.SQUARE
matched 3101 pose pairs, scored 3101 (join 1.00, median gap 0.0 ms)
propriety caveat: pairwise scores are strictly proper only under a
honest reference sigma and independent errors; both violations push
conservative, so NEES_pair lower-bounds miscalibration.
pairwise median NEES 56.1 (calibrated: 2.37)
pairwise scale gap k >= 23.7, >=4.87x too tight per axis (lower bound)
verdict: optimistic (ANEES 71.7 vs chi2 interval [2.91, 3.09])
An elevated pairwise NEES certifies overconfidence with no reference consulted. Filter A is aligned to filter B directly and the difference is scored under the summed covariances. Common-mode error and an understated reference covariance both push the statistic down, so the verdict is a lower bound on the miscalibration.
smfeval needs your filter's per-pose covariance, not just its poses, but you do
not have to adopt the SQUARE format to provide it. Two on-ramps are documented
in SQUARE_spec.md.
- Wide TUM. Standard TUM pose columns plus the 21 row-major lower-triangle entries of the 6x6 tangent covariance (29 columns total).
- Sidecar file. Plain TUM poses plus
--cov cov.txtwithtimestamp c11 c21 c22 ... c66rows.
smfeval nees est.tum ref.tum --cov est.cov --est-body-frame imu --ref-body-frame imuMost filters compute a covariance internally and never publish it. For four
popular LiDAR-inertial filters the export already exists.
exporters/ carries the audited few-line diff that makes
FAST-LIO2, Faster-LIO, Point-LIO, and I2EKF-LO publish their belief, each
with its pinned upstream commit, a bag-to-SQUARE converter, and a validation run
on a named public sequence. Contributions follow the PR template, with
smfeval validate --strict as the mechanical gate.
smfeval score est.SQUARE ref.tum produces the complete analysis.
=== smfeval scoring report ===
Synchronization
Mode: nearest
Pairs matched: 309 / 310
Dropped: 1
Timestamp gap (ms): median 0.04, p95 7.57, p99 8.55
Sync risk (v·Δt / σ): median 0.0099, p95 1.6363, p99 1.7755
[warning] 91 pairs (29.4%) exceed risk 0.3
Alignment
Gauge (declared): se3
Mode applied: se3 (6 DoF)
Fitted Δxyz: (-27.8424, 24.9711, 5.6239) m
Fit residual (m): median 0.0094, p95 0.0262
6 DoF removed over 32 m of trajectory
Scores
Translation CRPS: mean 0.004 m [95% CI 0.003, 0.006] (n=309)
median 0.003, std 0.003, min 0.001, max 0.014
block length (Politis–White): 24.4
Energy score: mean 0.009 m [95% CI 0.006, 0.011] (n=309)
median 0.006, std 0.006, min 0.002, max 0.028
block length (Politis–White): 24.6
Log score (translation): mean -8.017 [95% CI -10.644, -5.103] (n=309)
median -10.892, std 7.064, min -13.701, max 19.477
block length (Politis–White): 24.3
Interval score: mean 0.057 [95% CI 0.021, 0.095] (n=309)
median 0.010, std 0.092, min 0.008, max 0.402
block length (Politis–White): 24.3
Calibration
PIT uniformity (KS): p = 0.000 [warning] possible miscalibration
90% Mahalanobis coverage: 55.0% (nominal 90.0%)
Translation z-score: mean 1.63, std 1.02
Diagnoses (attribution → action)
[warning] sync_risk
A competing confounder: timestamp-matching error shrinks short-window Σ_rel the same way local over-confidence does.
· 29.4% of pairs exceed sync risk 0.3
→ Re-score with --sync=interpolate_ref to separate sync from a genuine calibration fault before trusting short-horizon verdicts.
Recommendations
- 29.4% of pairs have sync risk > 0.3; consider cross-checking with --sync=interpolate_ref to confirm calibration findings.
- 6 DoF removed over 32 m of trajectory; post-alignment residuals are biased low. Consider --n_to_align to fit on a prefix and score on the remainder.
- Coverage below nominal combined with KS p < 0.05 — the filter is over-confident (claimed Σ too tight, reference falls outside the predicted intervals); widen process noise. Miscalibration is unlikely to be explained by sync error alone.
Point-LIO on Oxford Spires christ-church-03, reproduced from
tests/fixtures/regression/real_point_lio. The report is built from:
- synchronization and alignment diagnostics;
- translation proper scoring rules (CRPS, energy score, Gaussian log score with its exact calibration/sharpness split, interval score), each with a stationary-bootstrap confidence interval;
- PIT/coverage calibration and windowed relative-pose calibration
(
--rpe-window); - track-frame bias/variance attribution;
- structured failure-mode diagnoses with recommended actions.
Only translation is scored, not orientation: a proper score on SO(3) needs a belief density whose normaliser is intractable for the natural rotation families, so rotation is left to future work (see docs/metrics.rst).
smfeval score --json prints the structured report to stdout, and --json-out
writes it to a file. Both follow docs/report.schema.json.
Why several scores? Each proper rule touches a different part of the predictive
translation distribution (bulk shape, tails, a chosen coverage level), so
no single number suffices. docs/metrics.rst explains
every metric and how to read it. SQUARE_spec.md documents the format and
conventions.
| Verb | What it does |
|---|---|
smfeval nees est ref |
three-line calibration verdict (median NEES, scale gap k, coverage) |
smfeval pair a b |
no-reference pairwise verdict (lower bound on miscalibration) |
smfeval score est ref |
full scoring report (--json/--json-out for machines) |
smfeval validate file |
header/row sanity checks (--strict is the exporter gate) |
uv sync && uv run pytestDocs live under docs/ (make docs). The test suite includes
property-based invariants (hypothesis) and seeded Monte Carlo power tests of the
verdict machinery itself (see tests/test_power.py).
If you use smfeval, please cite the software. GitHub's Cite this repository
button reads CITATION.cff.
Rønning, O. smfeval: probabilistic SLAM trajectory scoring. 2026. https://github.com/svendbot/smfeval
A paper describing the methodology and the audit behind it is in preparation,
to be released with slam_benchmark.
smfeval grew out of a systematic audit of uncertainty calibration in
LiDAR-inertial odometry.
slam_benchmark is the audit that
motivated this tool. The trajectory data used in fixtures and the notebook
derives from the
Oxford Spires Dataset
(CC BY-NC-SA 4.0; see the data license notes in those directories).